

Custom Jira-Bot for MS Teams using Node-Red and RethinkDB
Or why not to use a new approach


Today, I want to show you my little project I did at my spare time at work, to make my work more fun again. In a previous post, I wrote about my experience at work and how I found love again, to do my job and doing this project helped with it.
One part of continue my job, beside the Teams and the good working condition, is stuff like this, I can do, cause our client is stuck in I.T. from 2010 and I do not have to coach or improve processes.
Ok, let's dive into it. Two of my teams have to rely heavily on the tags feature of the Jira ticketing system. All cause the client does not allow us to use standard features, such as Environment, Team, Portfolio fields and similar fields.
Reason: It messes up our filters for billing. :-O
Anyway, to cope with the situation, we built most of our processes all around the tags feature of the Jira ticketing system. But since we are all human beings, stuff gets missed or forgotten or not followed. In addition, we also got two new PO, the old PO quit after 1,5h, cause of work overload and our difficult client. So two new PO's where hired to avoid the bad situation from the past. One PO for each team, should lower the workload and they can help each other and give them more standing at the client. But since they are both new to the project and din't had much training by the now gone old PO, and they are not used to such complicated ticket handling in Jira, I have to double sometime tripple check each updated ticket, to see if it is fill out correctly and the processes are fulfilled. I don't want to do it, but if I don't do it, it results in a somewhat chaos at the end of the Sprint, when billing or release time comes up.
Back to the topic. Before I wrote my bot, I sat down every morning with my coffee and went over my email inbox and checked for changed tickets emails, opened the ticket and verified it and correct it if necessary. But after I did this for a few weeks, it felt like a cumbersome and boring task. And part of my DevOps mindset said, "Can't I automate that somehow!?". So since I haven't to do much agile coaching for my teams or better for the client, I used my spare time to write me a notification bot.
Of course I could try to write a bot for MS Teams, but then I would be locked in to that Microsoft Universe. So I decided to use a different approach. I use Node-Red for my weather station visualization at home, and it works perfect, so I decided I implement my bot with Javascript in Node-Red. And if possible with ready available standard nodes. And only with some custom Javascript if needed. I hope that with that approach to make the system flexible and easy transferable. So in case I want to replace MS Teams, with Slack, Yammer or Discord, it can be done relatively easily.
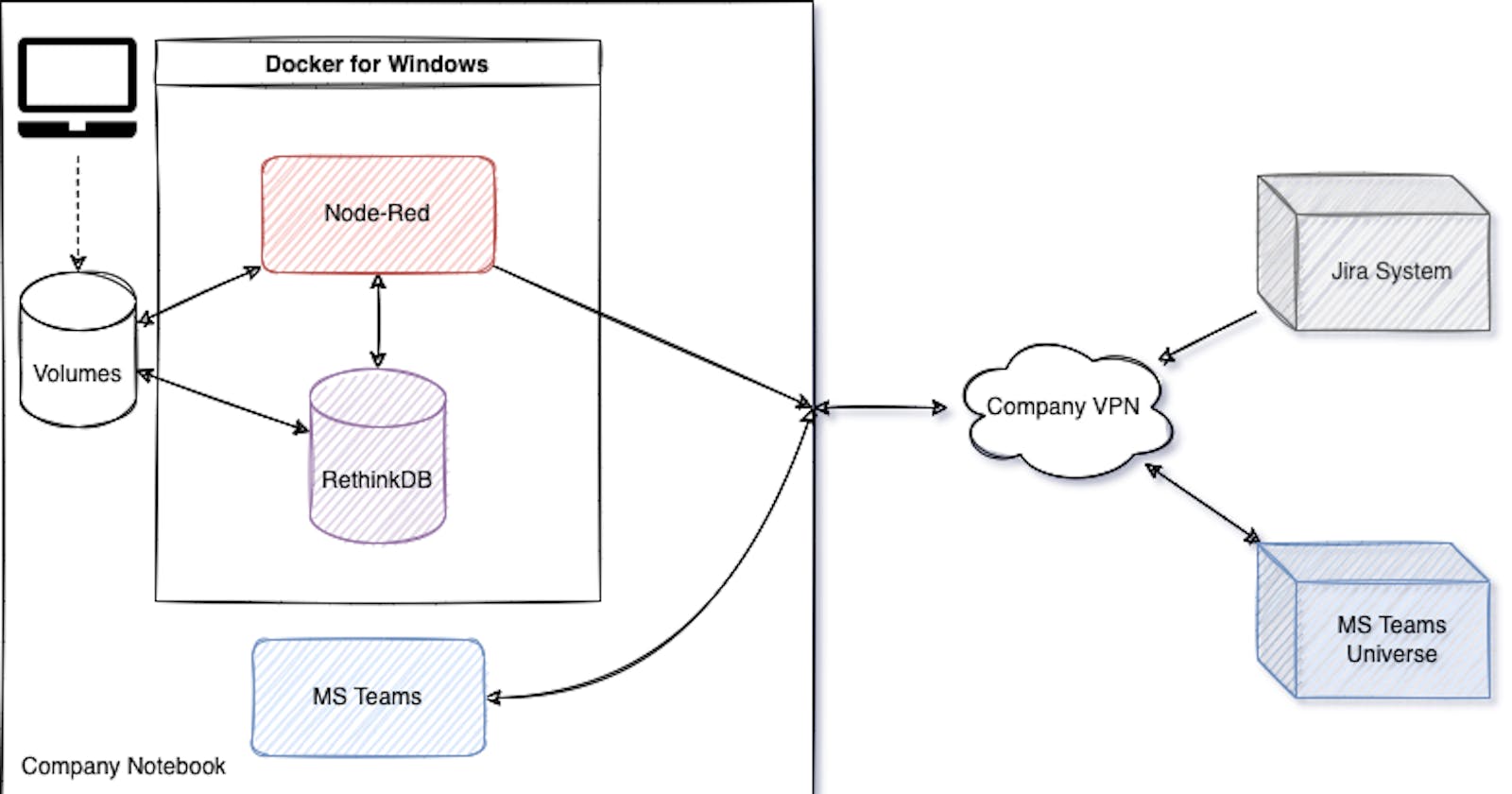
That's how I started my "Node-Red-Jira-For-MS-Teams"-Bot. Here is the simple architecture overview.
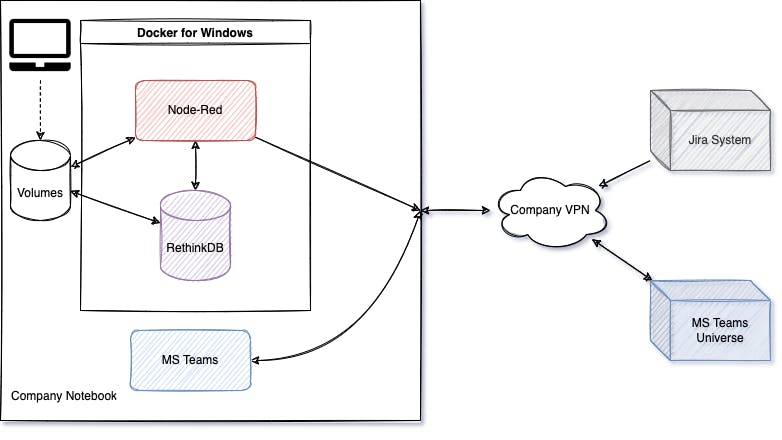
I decided for RethinkDB, cause in addition to save some basic information from the RSS feed, like Ticket No and update date, I also want to save the actual ticket information in json format, for later use. To be precise to try out Grafana+Loki or the ELK Stack for more detailed analysis of our tickets, at a later time.
Ok, lets continue. First I started with two simple flows in Node-Red. The RSS-Change flow and the RSS-Storage-Delete flow.
The RSS-Change flow is basically only for monitoring and debugging. Hence after everything was working, I disabled it. Here is the flow:

Design decision here, was simple. Simple use the monitor node that comes with the RethinkDB nodes and dump it to a debug node.
The RSS-Storage-Delete flow was necessary, to clean out the store once in a while. Cause it seams a good idea to have a wipe once in a while and start fresh. Here is the flow and the code:

global.set('items', {})
return null;
Design decision here, was to handle all the data storage in the database or do some caching. I decided to do caching in the global storage of Node-Red. Hence the simple delete code.
Next I started out to create the flow for getting the Jira changes. First I needed a start point. Usually if you have nothing else, you use a trigger node in Node-Red. With this trigger node you can trigger the execution by click or e.g. as a timed trigger. In my case I deceided for 15 min trigger event.
Next step getting data. Since Jira offers a RSS feature for jql-queries, it was easy to convert the Kanban Board query to a RSS feed url. The feed delivers all changes to tickets filtered by the specific jql-query. Problem here is simply, that you cannot specifiy what information you want to delivered in the result XML. Anyway, no problem here.
So here is the flow so far (doted line):

With the result XML at hand I could continue dealing with what I want to do with the XML. So I created a function node, dealing with the XML:
// extract payload item data
var data = msg.payload.rss.channel[0].item;
// get the items cache if it exists otherwise an empty dictionary
var items = global.get('items') || {};
var list = [];
// loop over the elements in the payload data
for (var i = 0; i < data.length; i++) {
var title = data[i].title;
var datetime = data[i].pubDate[0];
// since there is no jira ticket key field, it must be extracted from the title via regex
var rx = /^\[(TICKET\-\d*)\]\s.*$/;
var arr = rx.exec(title);
var key = arr[1];
// If not in cache, store it
if (!(key in items)) {
items[key] = datetime;
list.push(key);
} else {
// if in cache and it was updated, store it
if (items[key] < datetime) {
items[key] = datetime;
list.push(key);
}
}
}
// no loop over each cache item and create a new updated msg for each ticket and send it to the next node
Object.entries(items).forEach(function([key, value]) {
var newMsg = {};
if (list.includes(key)) {
newMsg.topic = 'Update';
newMsg.update = { "key": key, "value": value };
node.send(newMsg);
}
});
// save the cache to the global storage
global.set('items', items);
// eliminate the XML message
return null;
So nothing fancy, just some plain looping, restructuring, creating and sending messages, and bookkeeping. Ja experienced Javascript programmers will see some problems, especially with, what happens in case of errors. I have it on my list. But I follow the good old principle:
First make it run, then make it fast and at last make it pretty and safe.
So with the essential information extracted, what to do with the messages. Here the flow so far:

Of course debugging. Done with a debug node. Actually two debug nodes. One for the whole message and one for only the payload.
Next addition persistence of the RSS tickets. Since the whole system is running on my company notebook in Docker for Windows, it will shutdown every evening. So I would possible loose the data I stored in the Node-Red cache so far. Hence I needed to persist the cache. Solution store the information in a database. In my case I selected RethinkDB (why not use a different approach and path).
The RethinkDB got a new very simple table "rss_jedi" - btw. Jedi is just a nickname the teams chooses for themself -, where I could store the items array and each timestamp for the item. To do this was not so problematic. Or wasn't it.
Well I ran into a problem. I don't know why, but if an RSS item was already in the RethinkDB table, it was not overwritten or replaced, as I configured in the conflict argument. Instead it created a new entry in the DB. Hence I soon had many duplicates in the RSS DB.
r.table("rss_jedi").insert(
msg.update, { conflict: 'replace' }
);
So even I had a conflict handling configured, it did not work for the RSS items persistence. So I had to use
r.table("rss_jedi").filter(r.row('key').eq(msg.update.key)).delete();
to delete the entry in the DB first, and then I could update it with above insert code. And since I had to make sure it happens sequentially, I needed a wait node, which delayed the insert message for 5s, so the previous delete was complete. This is a workaround, since the RethinkDB nodes don't have output connectors, hence you cannot daisy chain them. The progress so far:

Finally only two more challenges to do. First, what happens when I restart the flow, when I start Docker for Windows in the morning. How do I fill the cache. For that I simply used the trigger at the beginning and a function node with the following code:
// Data from the RethinkDB RSS DB
var data = msg.payload;
var items = {};
// loop over the DB entries and fill the cache
for (var i = 0; i < data.length; i++) {
var key = data[i].key;
var datetime = data[i].value;
if (!(key in items)) {
items[key] = datetime;
}
}
global.set('items', items);
return null;
The experienced viewer will note a problem right away. Isn't that cache filling triggered every 15 minutes, too. Yup, it is. But since in the normal case, the persistent cache is equal to the Node-Red cache, it is overwritten with the same data. But you're right a better solution should be found.
And at last, the last challenge. I mentioned earlier that I want to persist the changed tickets, for later use with Grafana/Loki or ELK, so I needed a flow for that, too. So for that I need the ticket information first. Luckily with Jira and the REST Api it is trivial, hence this simple code:
msg.url = "https://xxx/jira/rest/api/2/issue/" + msg.update.key + "?expand=changelog"
msg.payload = {}
return msg;
I simply use the REST Api URL, add the Jira ticket key, add the desired change-log and send this into a http request, which uses the json data header and the payload and url to retrieve the ticket data and stores it into a new RethinkDB table. Funny thing here is, that here the conflict solving worked. Here is the code:
r.table('issues').insert(msg.payload, { conflict: 'replace'});
And here the final flow:

And now you ask, where is the message part for MS Teams. Here it is:

It is relatively easy. I used the RethinkDB monitoring node for changes. Which gets a message for the changes. I put the messages payload into a function node, which creates the http request code for the MS teams webhook and sends out the http request to the MS teams universe, which promptly triggers the message in my local running MS Teams. How to add a webhook to MS teams, can easily googled, hence I did not described it here. Here is the code for the function node:
var newMsg = {};
newMsg.headers = {
"Content-Type": "application/json"
};
// deleted nodes have an empty new_val, hence I ignore it
if (msg.payload.new_val) {
newMsg.payload = {
"@type": "MessageCard",
"@context": "http://schema.org/extensions",
"themeColor": "0072C6", // light blue
"summary": "Summary description",
"sections": [
{
"activityTitle": msg.payload.new_val.key,
"text": "Ticket " + msg.payload.new_val.key + " was updated! (https://xxx/jira/browse/" + msg.payload.new_val.key + ")"
}
]
};
node.send(newMsg);
}
return null;
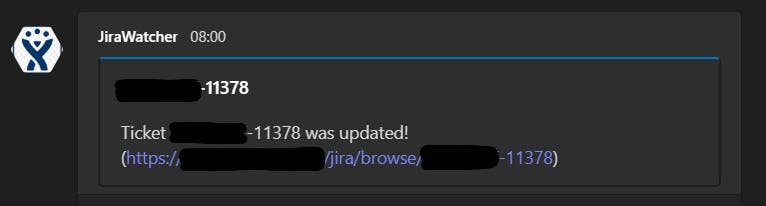
And here what MS teams spits out:
For the grand finally, I thought, it would be good, to have a flow to update all tickets with the latest information, just in case there is a problem and I want to make sure I got all tickets covered. Hence I created this flow:

This flow is straight forward. Get all the cached items, request the Jira ticket information and update the RethinkDB. Here is the code for the fetch items function node:
// get the cached items or an empty dictionary
var items = global.get('items') || {};
// loop over the cache items and request the jira ticket information
Object.entries(items).forEach(function([key, value]) {
var newMsg = {};
newMsg.topic = 'Fetch';
newMsg.url = "https://xxx/jira/rest/api/2/issue/" + key + "?expand=changelog"
newMsg.payload = {}
node.send(newMsg);
});
return null;
Well I instantly ran into two problems. The Jira server hand a request limit of 10 requests per second, so since my loop was firing so fast, I had to add a delay node, so my account wasn't locked and in case of a locked message I cannot update the DB. So I added a switch node, that checks if the response from the http request is json or normal http, and in case of http, it routes to a debug node, otherwise it stores the json result, which is the Jira ticket information into the RethinkDB.
So all in all it was a very unspectacular development of these flows. Of course you have to go through a learning curve and learn what nodes do, what they can provide, what you have to do programmatically, but if you look at the complete flow plan, it is very small. All in all it was a great experience to develop in a new way and doing it in a System normally only used for home automation or visualization. And it shows how flexible Node-Red with the node.js base has become. I even think about it, trying to use it as test tool for some purposes.
Sure in the background each of the nodes has many more Javascript code, but I did not have to write it, I can simply use the nodes. And ja, you have to find the right nodes, but with the basic set of nodes you can do a lot of stuff. The only custom nodes I added was the RethinkDB nodes.
And at last here is the complete flow, how it runs on my Docker for Windows instance with Node-Red and a RethinkDB:
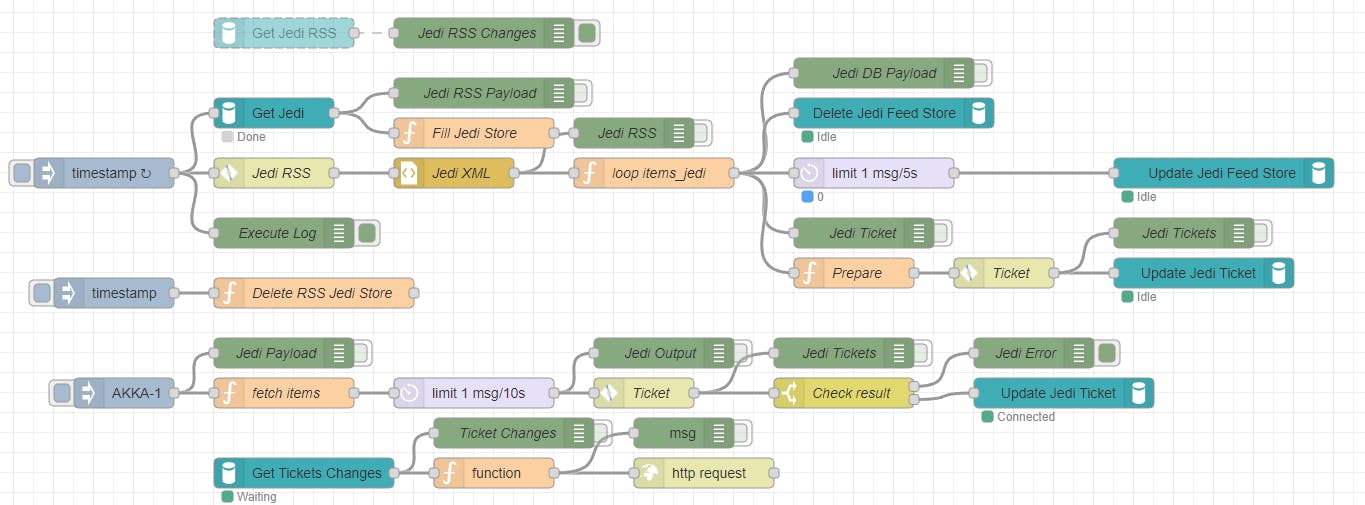
Ja, hard-core node.js or python programmers or automation specialist would say, I could do this much easier so and so, with even less code and system requirements. I know that. That's not the point I wanted to accomplish. I wanted to do a thing I haven't done before in a new system I've rarely used before. And that what I did and I had success - at least in my eyes - with it.
Ok, hope that was as helpful for you as it was fun for me. At least it spiced up some weeks in my otherwise not so interesting job. And I will continue to use this path, cause I want to add more flows to fill Grafana+Loki or ELK. And of course in the end i want to make my flows safe and error resistant and also try to use sub-flows for more structure. So plenty of fun to come.
As always apply this rule: "Questions, feel free to ask. If you have ideas or find errors, mistakes, problems or other things which bother or enjoy you, use your common sense and be a self-reliant human being."
Have a good one. Alex