

My (current) solution to push Jira ticket events via Node-Red to Elasticsearch...

Well, I worked as:
- Technical Consultant
- Developer
- Build Engineer
- Release Manager
- DevOps Engineer/Consultant
- System Integrator
- Scrum Master/Agile Coach
- Technical Project Lead
Introduction
So, due to my Easter break, my Node-Red/Jira update was a little delayed. Ja, not much to do at work. Our car manufacturer client, still is reluctant to adapt to Scrum, so no need on my side to do Team Building Workshops and/or Scrum/Kanban trainings. So I'm reduced to drop a piece of wisdom once in a while about the correct meaning of Scrum terms.
Latest "highlight" from our client. The Manager in charge of the whole Department, said, he wants from us ASAP the velocity we have left for the next release of the product. So I couldn't resit and correct him, that the "velocity" is calculated from the achieved SP of the past sprints. And that the "capacity" the team has left to achieve or better over-achieve the planned Sprint goal is documented at the agreed confluence page. Well, what can you say, our client is how he is. If he doesn't want to change you cannot force him to. Anyway, that means more time for my little project, hence back to my Node-Red/Jira project extension to Elasticsearch.
In the last post I described how I implemented the push of ticket change information via Jira RSS to MS Teams via Node-Red. As I also mentioned I wanted to extend my Node-Red flow to also push the information to Elasticsearch, to do some Kibana Dashboards for KPIs and other analytics.
So my Jira RSS flow in Node-Red downloaded the information from changed tickets via Jira Rest API (/rest/api/2/issue/?expand=changelog) to a RethinkDB.
With that url I get all the essential information about a Jira ticket, including the "changelog". And that "changelog" is exactly what I need to generate the information for Elasticsearch.
So here is the new flow for the push to Elasticsearch and the needed modules for Node-Red:
Part 1: Modules
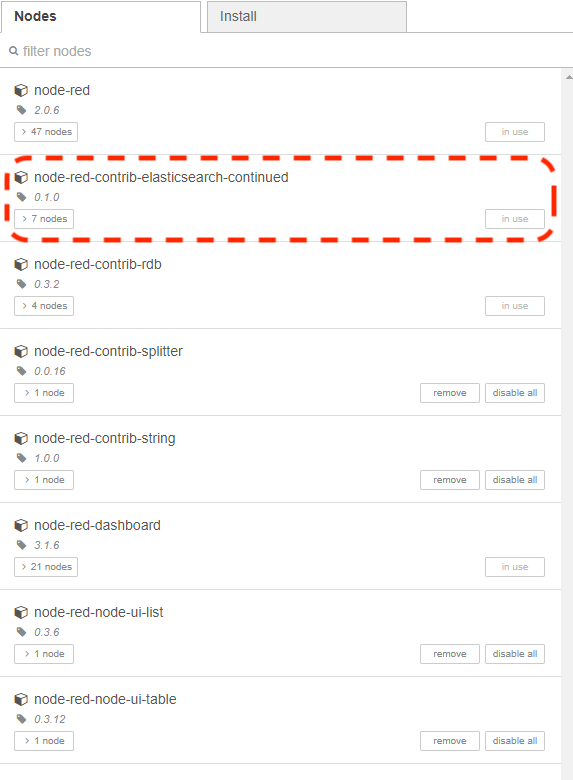
Part 2: Addition of a flow link to the elastic push flow

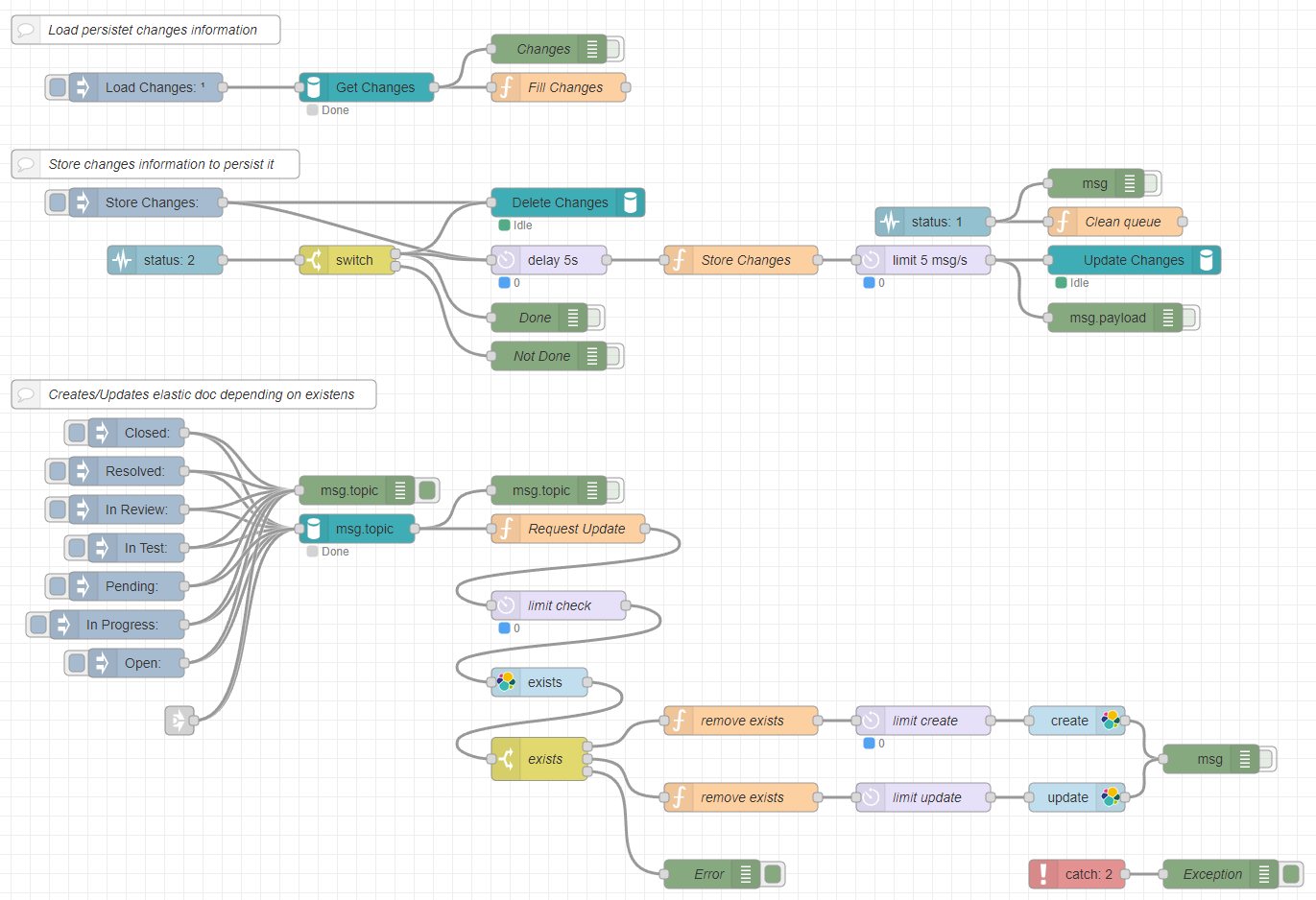
Part 3: The elastic push flow
Part 1
To push information via Node-Red to Elasticsearch, I use the free Node-Red module "node-red-contrib-elasticsearch-continued". I used this module, because the source code is available on guthub.com and it has the nodes (exists, create, update) I needed to do my flow.
Part 2
Ok, in Part 2 there is only one small addition the flow out link:

With this flow out link, you can connect a flow on a different flow tab. What this link does, is that when a change is promoted to MS Teams, it also starts the elastic flow from Part 3. Very easy and simple, like a function call. And not much of a change of the existing Bot functionality.
Part 3
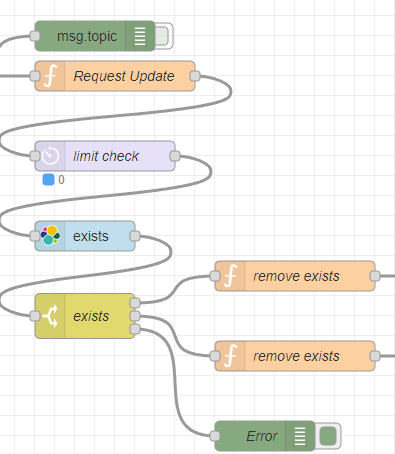
If you look at the Part 3, here lies the real change for the push to Elasticsearch.
Basically there are three components:
The actual push to elastic flow:
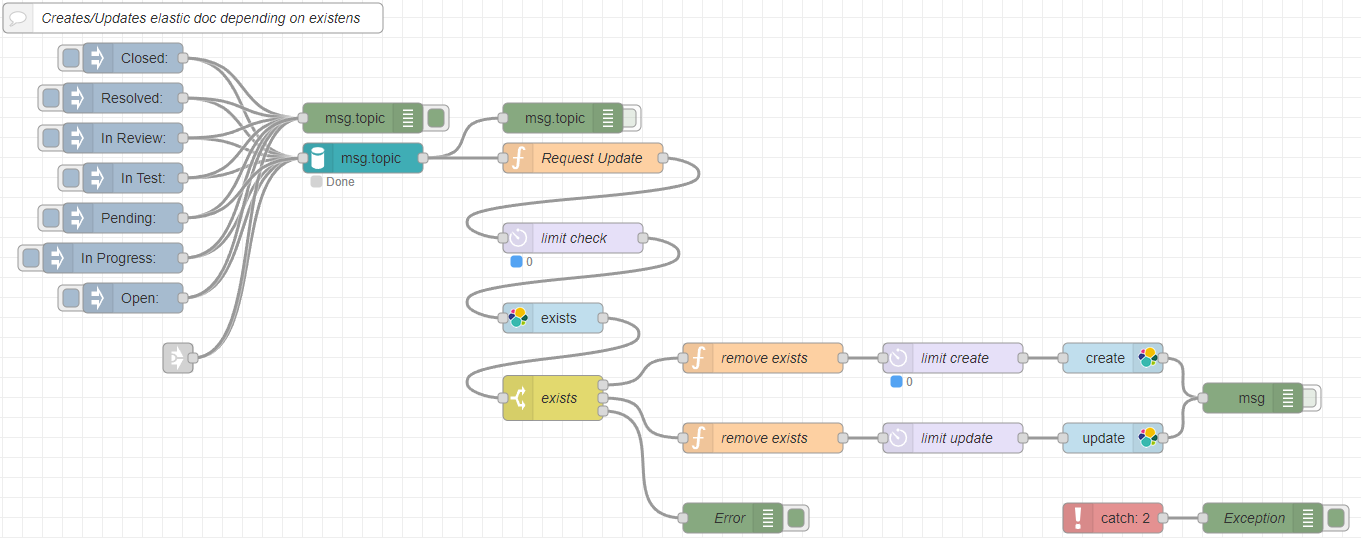
The initialization of the event information during Node-Red startup:

The persistence of the pushed events:

Component "Persistence"
Ok, let's start with Component "Persistence". Again, I use RethinkDB to persist the control variables. As already mentioned I do this, to avoid that duplicate entries are created over and over again. And this spam is cloaking up Node-Red and Elasticsearch.
Secondly currently I have no clue how I could achieve it otherwise in Node-Red.
Also during testing I found out, that my local docker setup can only handle so many storage operation, before it shuts down. Hence I needed to introduce a throttle mechanism. Luckily Node-Red has a node "delay" for that. And I could very easily limit to send of messages to 5 messages per second. Problem solved
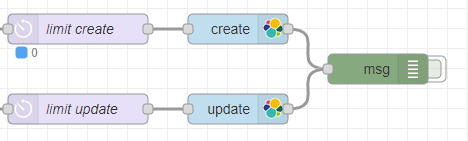
But let's start at the beginning. So the manual trigger "Store Changes", is only for testing the store process or do manual saves. The actual trigger is the "status: 2" trigger.
The status node is a node that listens on changes of other Node-Red nodes. In my case I listen on the two nodes "limit create" and "limit update". Here I listen for the queue length. To use this information, I use a switch node, where you can evaluate values from a message. Here I check if the queue length is greater 0. If greater, then the port 2 of the switch is triggered. If the queue is empty, the Done port 1 is triggered.
As I mentioned I have to make sure to avoid duplicate entries. Hence I created a, Ja I know not very good, solution. I delete (r.table("changes").delete();) the changes table in the RethinkDB. I also delay the store for 5s to hope the deletion is through by then. After that I create the store messages for the RethinkDB.
var _queue = global.get('queue') || [];
var _changes = global.get('changes') || {};
Object.entries(_changes).forEach(_item => {
var _id = _item[0];
if (!(_queue.includes(_id))) {
_queue.push(_id);
// Create new msg
var newMsg = {};
newMsg.topic = "update";
newMsg.payload = { "id": _id, "value": _item[1] };
node.send(newMsg);
}
});
global.set('queue', _queue);
return null;
After a while I noticed that a ton of save changes events are generated, since the "0" queue event is happening very often, since the handling of Node-Red is so freaking fast. At one point I had over 1 million events scheduled, even only about 1000 tickets are stored.
Hence I had to create a queue to control what message was already sent, to reduce and cleanup this load. But with that I needed a mechanism to delete the queue, when all change messages are stored to the RethinkDB.
But that was very easy. I used the status node again, to check for an empty queue of the store messages.
var _count = parseInt(msg.status.text);
if (_count == 0) {
global.set('queue', []);
}
return null;
With that out of the way, I had a safe and reliable way to persist every change to the RethinkDB.
Component "Startup"
Ok, lets continue with Component "Startup", it is actually the easiest of those three. To avoid to save duplicates, I keep for each ticket key, a record what was the last event I pushed to Elasticsearch. So I can first of all avoid to push all events over and over again and of course do some optimization.
With the saved last event number, a simple compare is sufficient to filter out already sent messages. This is very easy, cause the Jira changelog keeps a value with the count of change records. But more later.
As you can see, there is a little Javascript needed for the initialization:
var _data = msg.payload;
var _changes = {};
for (var i = 0; i < _data.length; i++) {
var _key = _data[i].id;
var _value = _data[i].value;
if (!(_key in _changes)) {
_changes[_key] = _value;
}
}
global.set('changes', _changes);
return null;
This little script simply converts the information delivered with msg.payload I get from the Get Changes node from the RethinkDB table, to key/value pairs in a global flow variable changes.
To trigger this script whenever Node-Red starts, I use a special functionality from the Node-Red trigger node. This node has an option to trigger the following nodes after a delay. I simply use the standard delay of 0.1s. So after 0.1s the load of the changes to the internal Node-Red global storage is triggered. Very handy!
Component "Push"
Finally lets describe the "Push" Component. The actual Elasticsearch push.
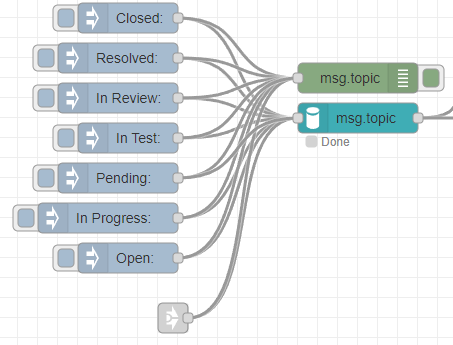
The start of the flow looks very complex, but it really isn't. Actually only the link in node is relevant.
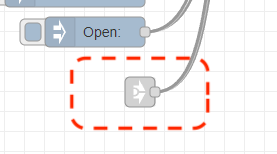
This node is linked to the Bot trigger link out flow. So this flow in trigger is triggered when a change was registered. Since the msg generated by the bot flow contains the type of change in the message topic, I can use this information to request the ticket information from RethinkDB:
r.table('issues').filter(doc =>
doc('fields')('status')('name').match(msg.topic)
);
The information delivered in the meassage payload can then be converted in the information I want to push to elasticsearch. Here is the Javascript for the "Request Update".
var _changes = global.get('changes') || {};
var _payload = msg.payload;
var _key = _payload.key;
var _status = _payload.fields.status.name;
var _kind = _payload.fields.issuetype.name;
var _team = '-';
if (_payload.fields.labels.includes('TEAM-1')) {
_team = 'TEAM-1';
} else if (_payload.fields.labels.includes('TEAM-2')) {
_team = 'TEAM-2';
} else if (_payload.fields.labels.includes('TEAM-3')) {
_team = 'TEAM-3';
} else if (_payload.fields.labels.includes('TEAM-4')) {
_team = 'TEAM-4';
}
// create new entry for a new key/ticket
if (!(_key in _changes)) {
_changes[_key] = {
stamp: new Date().toISOString(),
total: 0,
last: 0
}
}
var _idstart = 100;
var _total = _payload.changelog.total;
var _stamp = new Date().toISOString();
var _current = _changes[_key];
var _count = _current.last;
// if no new changes we are done
if (_current.total >= _total) return null;
// loop through the changes
for (var _i = _current.total; _i < _total; _i++) {
var _entry = _payload.changelog.histories[_i];
_stamp = _entry.created;
_entry.items.forEach(_item => {
// New id from key, id start + item count
var _id = _key + '_' + (_idstart + _count++);
// Create new entry for elasticsearch
_from = (_item.fromString) ? _item.fromString : '';
_to = (_item.toString) ? _item.toString : '';
if (_item.field == 'description') {
_from = (_from) ? _from.substring(0,49) + '...' : '';
_to = (_to) ? _to.substring(0,49) + '...' : '';
}
_rdate = null;
if ('resolutiondate' in _payload.fields) {
_rdate = _payload.fields.resolutiondate;
}
// Create new msg
var newMsg = {};
newMsg.documentIndex = "tickets";
newMsg.documentType = "message";
newMsg.documentId = _id;
newMsg.payload = {
"@timestamp": _stamp,
"key": _key,
"kind": _kind,
"status": _status,
"reason": (_payload.fields.customfield_13000) ? _payload.fields.customfield_13000.value : '-',
"resolution": (_payload.fields.resolution) ? _payload.fields.resolution.name : '-',
"resolutiondate": _rdate,
"team": _team,
"effort": (_payload.fields.customfield_12401) ? _payload.fields.customfield_12401.value : '-',
"points": (_payload.fields.customfield_12006) ? _payload.fields.customfield_12006 : null,
"author": _entry.author.displayName,
"change": _item.field,
"from": _from,
"to": _to
};
node.send(newMsg);
});
}
_current.last = _count;
_current.total = _total;
_current.stamp = _stamp;
global.set('changes', _changes);
return null;",
Here again, I ran into a problem. My docker setup was not powerful enough to handle all the messages. So I once again hat to add a throttle the message to the "exists" check against Elasticsearch.
Since the Node-Red Elasticsearch nodes I use, use the Elasticsearch Rest API, and the specifice implementation (see on top) does not have an upsert, I had to introduce an exists check, which basically just checks, if a message was already sent. Depending on the outcome the switch node decide to use the create or the update Elasticserach functionality.
But with this extra exists check, a new msg field "exists" was introduced, so I had to add some code to remove this extra info.
if ('exists' in msg) {\n delete msg['exists'];\n}\nreturn msg;
And once again, a throttle was needed, to not overload my system. And finally the Elasticsearch Rest API was called. There is not much to show, since the Rest API call is hidden in the node.js of the node, which simply takes the message and send it to Elasticsearch.
The only problem I ran into with these nodes, where that the nodes have a Elasticsearch configure node, with host and port fields, but the actual node.js does only use the host field, so the port field is not used. And you have to add the port to the host url, like http://localhost:9200. With that out of the way everything worked.
And here how it looked in Kibana:

Next step is to create some useful KPI dashboards out of this data. But that's another post in the future.
Conclusion
Well, what did I learn. Node-Red is a great flow based programming system. Very flexible, very variable and very easily extendable, if there are modules. There are many specialized nodes available, but sometimes with the problem of un-maintained code and/or documentation.
So sometimes you have to dig through github code to understand how they work or where the error lies in your flow. Like the not used port field.
I don't think it is production ready. For example I have now clue how to make a HA setup with it. But for local and simple automation task, definitely a great option.
And I learned, that I have to understand a lot more of the core nodes of Node-Red, to make efficient and beautiful flows. Currently I have to jump through extra hoops, like extra queues or other stuff, to keep the flow working.
So my flows are not perfect by any means. There is room to grow in the future. But for now I'm very satisfied with my success. I have my MS Teams bot, which informs me that a ticket was updated. I have the events in Elasticsearch with the changes. And now, I have the change to use the power of Elasticsearch and Kibana to do something with the data, outside of Jira.
Of course Jira has a lot of such feature already and with the Marketplace you can find a lot of nice extra extensions. But in an enterprise environment, there are some challenges with that. And with my solution I have it completely in my hands.
So thanks for reading and I hope you got some inspiration or a little bit Know How out of it.
As always apply this rule: "Questions, feel free to ask. If you have ideas or find errors, mistakes, problems or other things which bother or enjoy you, use your common sense and be a self-reliant human being."
Have a good one. Alex




