

It is (almost) over Or How I preserve Know How from a dying project...
Well, I worked as:
- Technical Consultant
- Developer
- Build Engineer
- Release Manager
- DevOps Engineer/Consultant
- System Integrator
- Scrum Master/Agile Coach
- Technical Project Lead
So it happened. As I mentioned in my summer update, one of the possibilities of my current work project is, that it will be canceled by our customer. And this option became reality, we are out by end of October at latest. A new contractor takes over! We are finishing the rest of our features we have committed to, till early October, and after that we only are on standby for warranty stuff. Ja, it is sad for the team and our company, but that how it goes sometimes. And honestly I'm not to sad about the cancelation. When you followed my blog, I ranted once or twice about it.
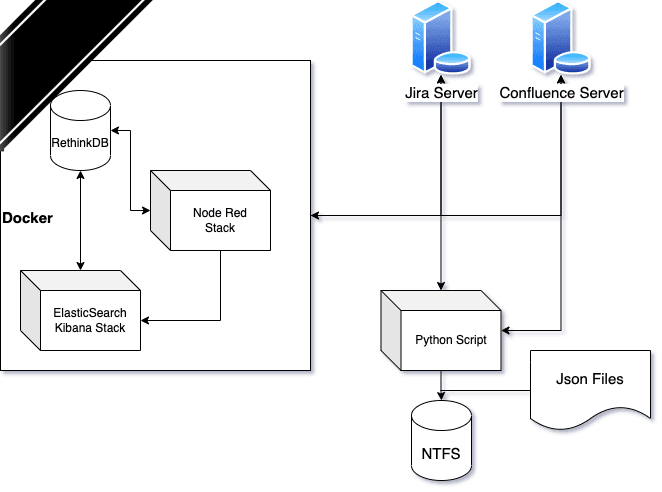
Anyhow, so the project is winding down. Ok, what to do with all the data in the RethinkDB, with all the Node Red flows, with all the Elasticsearch/Kibana stuff, with all the python code I wrote to calculate the KPIs and do the Confluence pages. Guess I have to come up with an idea to save the data, without compromising any important information about the customer and the project.
So let's do a short inventory.
The Database
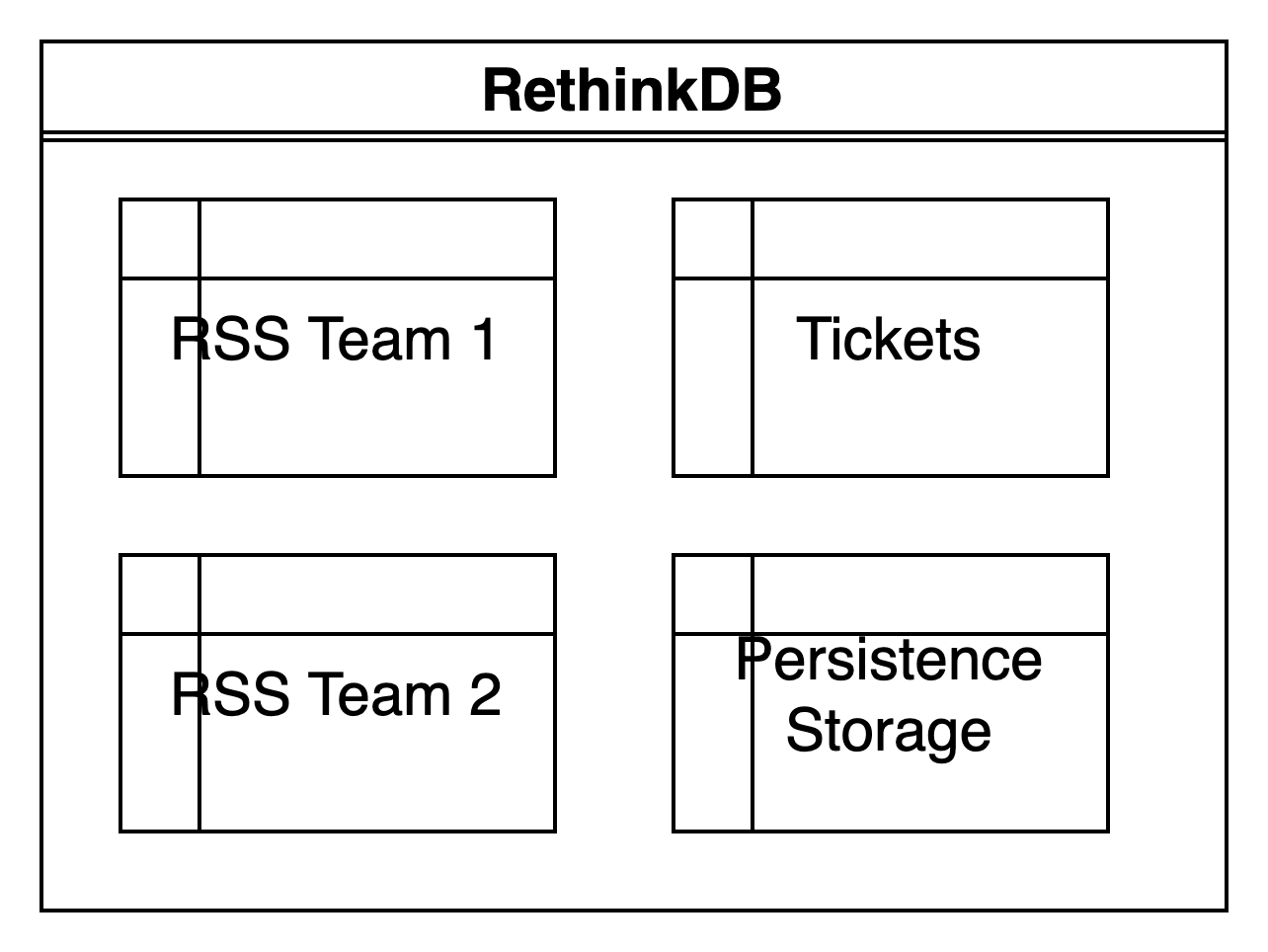
Ok, the database is, as I mentioned, the open source project RethinkDB a document based, no-sql database. I used only a few tables.
- One table for some persistent states, so Node Red can initialise some internal variables on startup and can continue at the last checkpoint.
- Two seperate tables with infomation form the RSS streams for each team.
- A table with all the tickets, starting from 2021, till last run of the update script. Currently over 2200 documents.
Node Red
- One flow for fetching the RSS feeds for the two teams and updating the ticket table and exporting it to Elasticsearch
- A flow for fetching all the closed tickets and storing/updating it in the ticket table
- Two flows to go over the closed tickets in the tickets table and updating the Elasticsearch information
Here is an example:
Kibana/Elasticsearch
- Two data sources. One for general ticket progress and one specific for state changes.
- Some special queries for in-depth analysis and some more or less generic Lens graphics.
Python Scripts
There is basically only one python script. It fetches info from jira, calculates kpis and then generate some special confluence pages. It is a cli based tool, with some simple scripting capabilities.
Well, that's it. That's what I did, to keep my not so Scrum-based project interesting for me.
The ideas
Ok, let's start with the Python script. Should be a quick win. Of course it is a proper python project, with setup, configuration and you guessed it a git repo in the project bitbucket. So most of the changes are in configs/settings only. There are only five specific references to tie my code to the customer project.
There are two configurable Jira JQL queries which are used to fetch the affected tickets for both teams. Then there are three settings (url, user, password) for the customer Jira server and the same for the Confluence server. And at last some hard coded stuff in the otherwise very generic confluence template pages.
Well, since the code is in a Bitbucket git repo, it can be easily exported and I can create a new local git repo. Easy since I use WSL2 with ubuntu on my Windows Laptop. The settings/configs/templates can be anonymized very quick and easy by deleting or replacing it with generic settings.
Since I maintain a requirements.txt with all the module references, I do not need to keep the virtual environment. I can simply delete it. With that generic code in a local git repo, I should be able to very easily zip it and store it. And if I need it for a possible new Scrum project with Jira/Confluence it can be reused very easily. Simply adapt the JQL(s), the urls, users and passwords, and of course the confluence templates. Which I assume will be a bit more work, since it depends what the new Confluence offers for plug-ins.
Guess, I can do this preservation very quick, shortly before my customer project shuts down for good and I no longer have access to the bitbucket git.
One down, three more to go.
Let's continue with Elasticsearch/Kibana. The good thing is, that I didn't use to much specific features from them. Just the basic stuff. No calculated fields, no special developer configuration stuff, no special plug-ins, just plain Kibana/Elasticsearch stuff. As far as I know you can backup or export some settings and diagrams configs. But if not, it doesn't matter, since I built it once, so I can built it again. And what about all the stored data, you might ask. I won't safe or export it, since it can easily re-generated via the Node Red flow I have for that. And it is only useful for a post-mortem of the project, which I strongly hope I can convince my Project Lead and my Department Lead of, so we can have some insights and learnings for future projects.
The Kibana/Elasticsearch setup should be fairly easy to adopt it to a new Scrum project. I assume, another quick win for me.
Two done, two to go.
Next is Node Red. Node Red will IMHO a quick win, too. There is an export flow function, to export the all flows as a json to the clipboard, so it can easily copied and pasted to file. Of course there are some references to Jira and passwords stored. But since they are encrypted they are not in clear text, they can simply removed with search and replace. Of course the the RSS streams need to be removed as well. This is not a major headache, since RSS feeds can easily be generated and very easily retrieved from a JQL query in Jira. And since the JQLs have to be adopted to a new SCRUM Project anyway, no problem at all.
Hmm, of course I need some screenshot, too. Just to make sure, I get the same layout and the same plug-ins installed for the new Scrum project. And most importantly the used Node Red plugins and version numbers. Since there is no obvious way to save this information. At least if you don't want to dig around in the config files. Which I do not plan to do.
Well, sounds this one is also an easy win.
Only one left. The Database.
The Database will require some more work, since it contains sensible data.
- First, I have to make sure, that no compromising data is exported.
- Secondly, I have to make sure, that I have all the data I need for experimenting with different visual frameworks (eg. eGraph or Seaborn). And I can reconstruct the Elasticsearch/Kibana information, if I need it.
- And at last, filter all data (eg. summary, description, attachments - maybe transform it to some simple statistical data, like length, counts, types or so) which I do not need for KPIs, Graphs or analyzing.
- And I need to figure out in what format it should be exported.
I did a quick search last week and I found some very simple ideas how to export data from RethinkDB. And I've implemented an experimental script.
Very basic. Just loop through the tickets, and export each ticket as a separate json file. Since the Jira Json structure is very large, I spare you an example, cause I don't think it is fun to scroll dozens of pages. Do a Rest Call with the Jira Rest API and you see what I mean. So here is the minimal script.
import json
from os import path
from rethinkdb import RethinkDB
r = RethinkDB()
r.connect( "localhost", 28015).repl()
cursor = r.table("tickets").run()
for document in cursor:
if 'key' not in document: continue
_key = document["key"]
print(_key)
_path = path.join('exports', 'data', _key+'.json')
with open(_path, "w") as jf:
json.dump(document, jf, indent=4)
And then I started a more in-depth script, which is still WIP, to achieve all my above goals. Some challenges were to overcome. Since the project language is german, there were many ä,ö,ü,ß used, which I had to deal with. Abd then the ',' and '.' dilemma in numbers.
But in general it is straight forward. Just a big loop with some filtering. And yes, it is not pretty or reusable. Just some throw away code, to export the data to excel, just before the project closes down, and my docker containers have to go to the bin.
from typing import NamedTuple
from common.utils import locate, read_json_data # some custom code I wrote years ago
Info = NamedTuple('Info', [('key', str), ('author', str), ('created', str), ('field', str), ('was', str), ('now', str)])
changes = []
count = 0
itemcount = 0
sp = []
for _file in locate(['*.json'], './exports/data'):
print(_file)
count += 1
_data = read_json_data(_file)
_key = _data['key']
_changes = _data['changelog']['histories']
for _change in _changes:
_author = _change['author']['displayName']
_created = str(_change['created']).replace('T', ' ')[:-9]
_items = []
for _item in _change['items']:
_field = _item['field']
if _field in ['Comment', 'description', 'Acceptance Criteria Checklist', 'Acceptance Criteria (old)', 'summary']:
itemcount += 1
_from = _item['fromString'][0:24].replace('\n', '').replace('\r', '') + '...' if _item['fromString'] else ""
_to = _item['toString'][0:24].replace('\n', '').replace('\r', '') + '...' if _item['toString'] else ""
if '\n' in _from:
_found = True
if '\n' in _to:
_found = True
if '\r' in _from:
_found = True
if '\r' in _to:
_found = True
if 'ö' in _from: # ö
_from = _item['fromString'][0:24].replace('ö', 'ö')
if 'ö' in _to:
_to = _item['toString'][0:24].replace('ö', 'ö')
if 'ä' in _from: # ä
_from = _item['fromString'][0:24].replace('ä', 'ä')
if 'ä' in _to:
_to = _item['toString'][0:24].replace('ä', 'ä')
if 'ü' in _from: # ü
_from = _item['fromString'][0:24].replace('ü', 'ü')
if 'ü' in _to:
_to = _item['toString'][0:24].replace('ü', 'ü')
if 'Ãœ' in _from: # Ü
_from = _item['fromString'][0:24].replace('Ãœ', 'Ü')
if 'Ü' in _to:
_to = _item['toString'][0:24].replace('Ãœ', 'Ü')
elif _field in ['Story Points']:
itemcount += 1
_from = _item['fromString'].strip().replace('.', ',') if _item['fromString'] else ""
_to = _item['toString'].strip().replace('.', ',') if _item['toString'] else ""
if _to not in sp: sp.append(_to)
if _from not in sp: sp.append(_from)
elif _field in ['Link', 'RemoteIssueLink']:
itemcount += 1
_from = str(_item['from']).strip() if _item['from'] else ""
_to = str(_item['to']).strip() if _item['to'] else ""
else:
itemcount += 1
_from = '\"' + _item['fromString'].strip() + '\"' if _item['fromString'] else ""
_to = '\"' + _item['toString'].strip() + '\"' if _item['toString'] else ""
_info = Info(_key, _author, _created, _field, _from, _to)
_items.append(_info)
changes.append(_items.copy())
with open('changes.csv', 'w', encoding='UTF16') as _ef:
for _change in changes:
for _item in _change:
_ef.write(f'{_item.created};{_item.key};{_item.author};{_item.field};{_item.was};{_item.now}\n')
print(sp)
print(count, itemcount)
I guess, I will build on that, especially I have only a few weeks left, before I do no longer have access and I have to do some other project closeout and administrative/housekeeping stuff.
Outlook
Ok, when all above ideas are implemented and I'm not wrong, I should get a local git repo which I can adapt for a new SCRUM project, a folder with some screenshoots and a flow json file, an excel file with 2000+ anonymized, essential Jira tickets for experimenting, and hopefully some exports from Kibana/Elasticsearch. All can be put in a zip file and stored for later use. Not so bad.
When I think about it, how much work and time I spent gathering all the information, programming, experimenting, just to present some KPIs (cause Jira was not offering it, or only in paid plug-ins, which you rarely can use in an enterprise setup) in a weekly meeting. And in the end I can boil it down to basically one zip file. Ja, sometimes I.T. projects are somewhat weird. But I spent a lot of work and time on stuff I can reuse, and that's a good thing. Of course I spent also a lot of work and time for stuff (useless discussions with our customer, how we should improve our processes) or escalation meetings over things, which just happened cause we have such a weird Scrum setup. And I might add, a very political (enterprise I mean) and more or less spontaneous customer.
Anyhow I learned a lot. Good things and things I do not want to do again. And that's good too. Or as Joda once said: "Ja, Failure a great teacher he is!", and I agree that is very true. For me, I'll bring this project to an end, hand over my tasks to the new Scrum Master from the new contractor and wish him/her good luck and a better fortune with the customer. And I hope strongly I'm out end of October and can find my closure.
And I hope our company, our Project Lead, my Department Lead, some responsible Sales people and I can have a post-mortem to wrap up the 30+ month journey with this oddly strange project.
As always apply this rule: "Questions, feel free to ask. If you have ideas or find errors, mistakes, problems or other things which bother or enjoy you, use your common sense and be a self-reliant human being."
Have a good one. Alex




